학교 프로젝트로 견종 분류 모델을 구축하고 XAI 알고리즘 중 하나인 LIME을 적용하는 프로젝트를 진행했고 논문까지 썼다.
주제가 여러 번 바뀐 탓에 딥러닝 노 베이스가 짧은 시간 내에 공부하고, 모델을 구축하고, 실험하며 논문까지 써서 놓친 부분이 많이 있어 방학 동안 배운 것들을 바탕으로 리펙토링을 하며 정리하려 한다.
프로젝트 개요
딥러닝을 이용한 견종 구별에 대해 근거를 제시하지 않는 데에 일반적인 사용자가 이해하기 어렵다. 이를 위해 반려견의 품종을 구별하는 딥러닝 모델을 구축한 후 이를 XAI 기법 중 하나인 LIME을 이용하여 분류 근거를 이미지로 보여준다.
Dataset
Class 선정
우선 분류할 견종은 총 10종으로 다음과 같이 선정했다.
- beagle
- golden retriever
- pekinese
- poodle
- shih-tzu
- white terrier
- samoyed
- pomeranian
- maltese
- cocker spaniel
우선 비글, 푸들, 시츄, 말티즈, 포메라니안, 골든 리트리버는 한국에서 가장 많이 키우는 견종이기 때문에 넣었고, 이것들과 닮은 몇몇 견종들을 추가하여 난이도를 약간 올렸다. 사모예드는 포메라니안과 닮고, 코커스패니얼은 골든 리트리버와 닮고, 화이트 테리어는 말티즈와 닮았다. (화이트 테리어는 내가 키우는 견종이라 넣었다)
Data 수집
종당 약 1000장 정도를 구하는 것을 목표로 데이터를 모았다.
Data는 캐글, 오픈 데이터 셋들을 긁을 수 있는 것들을 다 긁어모았다. 그런 후 부족한 양은 구글에서 [종이름] image 와 같은 검색어들로 크롤링을 하여 최대한 모았다.
구글에서 크롤링을 할 때 스크롤을 일정 횟수 이상으로 내리면, 검색어와 관련이 없는 이미지들과 중복되는 데이터가 대부분이어서 생각보다 많은 데이터를 얻을 수 없었다.
그리고 크롤링으로 구한 데이터들은 정제가 되지 않은 데이터들이기 때문에 하나하나 눈으로 확인해가며 이상한 데이터를 지우며 정제하는 과정을 거쳐야 했다. 또한 중복된 데이터들이 많았기 때문에 중복 데이터를 거르는 과정도 거쳤다. 중복 데이터는 해쉬값을 이용하여 제거했다.
아래 코드는 중복 이미지를 제거하는 코드다.
target = [
'beagle', 'cocker_spaniel', 'maltese',
'pomeranian', 'poodle', 'golden_retriever',
'samoyed', 'shih_tzu', 'white_terrier', 'pekinese']
for breed in target:
jpg_list = glob.glob(f'./data/{breed}/*.jpg')
hash_set = set()
for path in jpg_list:
img = Image.open(path)
hash = imagehash.phash(img)
if hash in hash_set:
if os.path.isfile(path):
os.remove(path)
print(f'Delete {path}')
else:
hash_set.add(hash)위와 같은 과정들을 거치니 종당 평균 1000개의 데이터를 모으긴 했지만, 데이터가 가장 많은 종은 1500장, 가장 적은 종은 700장이었다. 데이터 불균형으로 인해 성능이 좋지 못하여 데이터가 가장 적은 종에 개수를 맞췄다.
Data 분할
데이터 양이 방대하면 train, validation, test 비율을 0.9 : 0.05 : 0.05 등과 같이 train에 대부분의 데이터를 둬도 된다고 배웠지만 데이터가 적었기 때문에 무난하게 0.6 : 0.2 : 0.2로 나눴다. 나눌 땐 랜덤 하게 나눴다.
Model
처음엔 모델을 스크래치부터 구축하고 싶었지만 데이터의 양이 부족해서인지 스크래치부터 구축하는 것은 성능이 너무나 안 나와서, transfer learning을 했다.
모델 선택
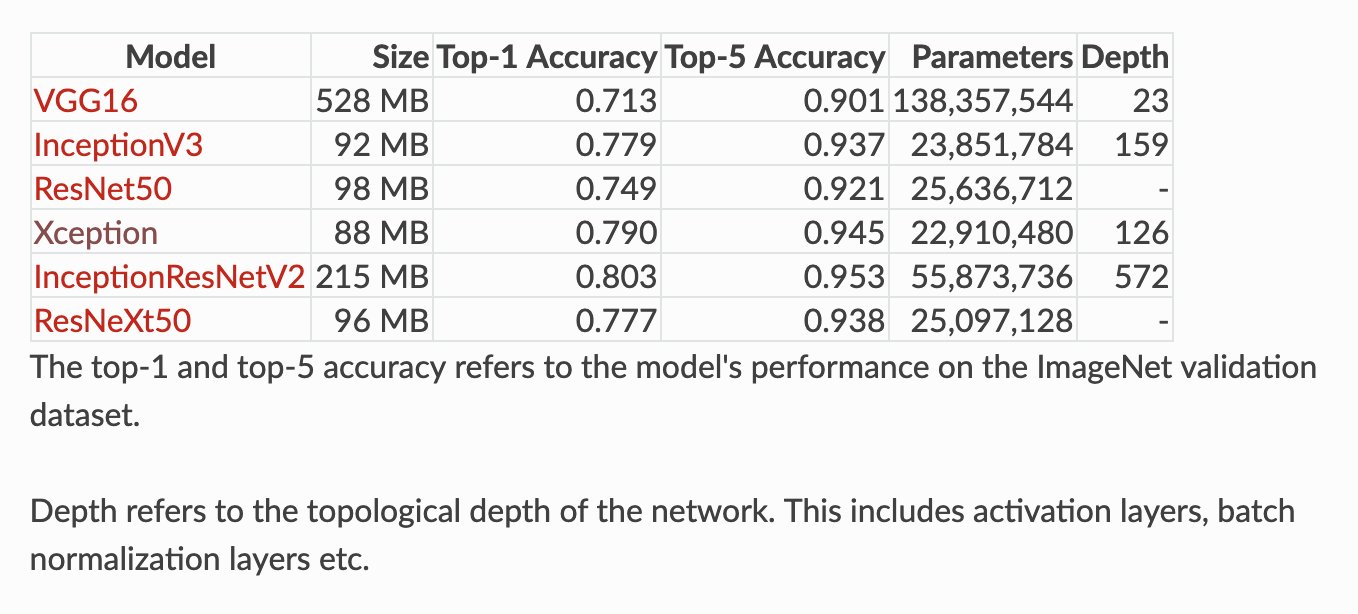
컴퓨팅 파워 이슈로 학습 한번 한 번이 너무 오래 걸리기 때문에 다양한 실험을 해보기 위해 최대한 정확도는 높으면서 연산 양은 적은 모델을 사용하길 원했다. 그렇다고 Resnet18 같은 작은 모델을 사용하기엔 정확도가 너무 아쉬워서 정확도가 90%이상 나오는 모델을 사용하기로 했다.
위의 이미지를 보면, Xception 모델이 사이즈와 파라미터 수가 가장 적음에도, 두 번째로 높은 정확도를 보인다. 가벼우면서 정확도는 높기를 원하는 나에게 딱 맞는 모델인 것 같아 Xception모델을 선택했다.
ResNet50과 InceptionV3, Xception을 동일한 loss함수와 optimizer를 사용하고, transfer learning을 하여 아웃풋 레이어만 학습시키며 실제 학습 속도를 비교해 봤는데 실제로 Xception이 가장 빨랐다. (정확한 수치를 적어놨었는데 없어졌다..)
Input size 결정 (Troubleshooting)
Xception은 input size가 (299, 299, 3)으로 설계된 모델이기 때문에 당연히 (299, 299, 3)을 쓰면 될 거 같았지만 input size를 정하는데 많은 역경이 있었다. 결론부터 말하자면 논문을 쓰는 시점까진 (224, 224, 3)이 최선인지 알고 (224, 224, 3)을 사용했고 나중에 구현에서 문제가 있었던 것을 알았다.
(299, 299, 3)으로 input size를 정했을 때, accuracy가 0.2 수준으로 떨어졌다. (224, 224, 3) 일 때는 0.9 이상으로 나왔기 때문에 정보의 양이 더 많은 299에서 더 정확도가 낮은 것이 이해가 되지 않아 가설을 두 개 세웠다.
가설 1 - 299보다 작은 데이터가 너무 많아 299로 키웠을 때 더 안 좋은 결과를 보인다.
가설 1을 확인하기 위해 이미지의 크기가 299보다 작은 것들의 개수를 카운트할 수 있는 코드를 짜서 확인해봤다.
cnt_299 = 0
cnt_224 = 0
for breed in target:
jpg_list = glob.glob(f'./{breed}/*.jpg')
for path in jpg_list:
img = Image.open(path)
if len(np.array(img)) < 299: cnt_299 += 1
if len(np.array(img)) < 224: cnt_224 += 1결과가 299보다 작은 데이터 수는 2069, 224보다 작은 데이터 수는 1034였다. 전체 데이터가 7561개인 것을 고려하면 약 30% 정도가 299보다 작은 이미지인 것이다. 이것을 보면 가설 1이 꽤 합리적으로 보인다.
또한 299보다 작은 데이터들을 다 제외하고 학습해본 결과 성능이 224보다 성능이 좋지는 못했지만 0.2와 같은 처참한 성능은 보이지 않았다.
가설 2 - 메모리가 부족하여 299로 데이터를 불러오면 데이터들이 깨진다.
가설 2를 확인하기 위해서는 이미지 크기를 320, 400등으로 키워봤다. 그러니 OS에서 메모리가 부족하다는 알림이 뜨며 프로그램이 죽었다. 그래서 메모리가 부족하면 불러오면서 깨지지 않고 프로그램이 죽어버린다고 판단을 했다.
위 두 가설을 테스트한 결과를 종합하여 가설 1이 맞다고 판단했고, 데이터 문제이니 (224, 224, 3)이 최선이라 생각했다.
하지만 데이터를 불러오는 구현 방식을 바꾼 결과 가설 2가 맞았다는 것을 확인했다. (논문 쓰기 전에 확인했어야 하는데 너무 늦었다..)
기존 구현
image_dir = [f'{data_path}/{breed}' for breed in target]
x = []
y = []
for i, breed in enumerate(target):
jpg_list = glob.glob(f'{data_path}/{breed}/*.jpg')
for img in jpg_list:
img = Image.open(img)
img = img.resize((299, 299))
img = img.convert('RGB')
x.append(np.array(img))
y.append(i)
print(f'{breed} * {len(jpg_list)} images are converted')위와 같이 모든 디렉토리들을 뒤지며 모든 이미지를 한 번에 메모리에 올린 후 작업을 했다. 이때 메모리가 간당간당하여 로드하면서 값들이 깨진 것으로 판단된다.
바뀐 구현
datagen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1./255,
horizontal_flip=True,
rotation_range=40,
width_shift_range = 0.2,
height_shift_range = 0.2,
shear_range = 0.5
)
generator = datagen.flow_from_directory(
'./data/train',
target_size=(299, 299),
batch_size=128,
class_mode='sparse',
classes=target,
seed=SEED
)위와 같이 tensorflow의 ImageDataGenerator을 이용하여 데이터를 batch 단위로 읽어왔다. Data를 batch 단위로 읽어오니 메모리가 부족한 일이 없어졌고, 당연한 결과겠지만 (224, 224, 3)보다 성능이 좋았다.
ImageDataGenerator을 이용하여 내 데이터를 뒤집고 자르고 확대하며 뻥튀기하는 data augmentation을 쉽게 구현할 수 있었다.
data augmentation을 유무를 실험해보니 하지 않은 것보다 하는 것이 더 좋은 성능을 보였다. 학습 데이터를 이리저리 굴리니까 모델이 더 다양한 상황을 학습해서 과적합이 방지되는 것으로 보인다. 이 부분도 논문을 쓰던 시점엔 잘 몰라서 시도하지 못했다.
학습 방법
transfer learning후에 fine tuning을 했다.
출력 부분만 내 데이터에 맞게 학습시키기 위해 기존 Xception모델에 출력부를 없애고, 새로운 Output layer를 추가하여 base model은 학습이 되지 않게 Fully-connected layer만 학습했다. 이것을 1차 학습이라 부르겠다.
그런 후 base model의 상위 레이어 몇몇도 내 데이터에 맞게 하기 조정하기 위해 레이어 일부만 학습 가능하게 바꾼 후 다시 학습한다. 이것은 2차 학습이라 부르겠다.
1차 학습 시에는 Fully-connected layer를 빠르게 학습시키기 위해서 optimizer에 큰 learning rate를 사용하고, 2차 학습 땐 base model의 잘 학습된 가중치가 너무 많이 조정되어 내 데이터에 과적합되는 것을 방지하기 위해 작은 learning rate를 사용한다.
optimizer는 SGD, Adam, RMSprop를 실험해 봤는데 SGD가 가장 좋은 결과를 보였다.
learning rate도 다양한 값들을 조합해가며 실험을 하여 최적의 값을 찾았다
과대적합을 피하기 위해 callback으로 early stopping을 이용하여 epoch 수 적당히 큰 값으로 정했다.
# 모델
base_model = tf.keras.applications.xception.Xception(
weights='imagenet', include_top=False, input_shape=(299, 299, 3))
avg = tf.keras.layers.GlobalAveragePooling2D()(base_model.output)
output = tf.keras.layers.Dense(len(target), activation='softmax')(avg)
model = tf.keras.Model(inputs=base_model.input, outputs=output)
# base model 학습 안되게 하고 1차 학습
for layer in base_model.layers:
layer.trainable = False
optimizer = tf.keras.optimizers.SGD(learning_rate=first_lr, momentum=0.9, decay=0.01)
early_stopping_cb = tf.keras.callbacks.EarlyStopping(
patience=2, restore_best_weights=True)
model.compile(
optimizer=optimizer,
loss=tf.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['accuracy'])
first_history = model.fit(
train_generator,
epochs=10,
validation_data=val_generator,
callbacks=[early_stopping_cb])
# base model의 상위 레이어 학습 가능하게 하고 2차 학습
for layer in base_model.layers[-trainable_layers:]:
layer.trainable = True
optimizer = tf.keras.optimizers.SGD(learning_rate=second_lr, momentum=0.9, decay=0.001)
model.compile(
optimizer=optimizer,
loss=tf.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['accuracy'])
second_history = model.fit(
train_generator,
epochs=1000,
validation_data=val_generator,
callbacks=[early_stopping_cb])
결과
test accuracy가 0.95가 나왔다. 성능이 매우 매우 만족스럽다. 논문 쓸 시점엔 0.92까지밖에 높이지 못했는데 나중에 더 끌어올렸다.


confusion matrix를 출력해보면 말티즈를 화이트 테리어라고 판단하는 경우만 많은데, class 선정할 때 말티즈와 구분하기 어렵게 하도록 화이트 테리어를 넣긴 했지만 생각보다 잘 못 맞춘다..
아마 둘이 닮은 영향도 있겠지만 화이트 테리어 데이터가 대부분이 크롤링한 데이터였기 때문에 퀄리티가 좋지 못해 그런 것으로 추측된다.
Github
최종 결과물
https://github.com/manguuu/xai-dog-breed-classification
GitHub - manguuu/xai-dog-breed-classification
Contribute to manguuu/xai-dog-breed-classification development by creating an account on GitHub.
github.com
논문 쓴 시점 결과물
논문에 이 깃헙 링크를 걸어서 수정해도 되는지 몰라서 포크 한 후에 위에 레포에서 작업했다.
https://github.com/Classufy/xai-dog-breed-classification
GitHub - Classufy/xai-dog-breed-classification
Contribute to Classufy/xai-dog-breed-classification development by creating an account on GitHub.
github.com
http://www.riss.kr/search/detail/DetailView.do?control_no=084eadfa92c7c31cc85d2949c297615a&keyword=XAI-based+Dog+Breed+Classification&p_mat_type=1a0202e37d52c72d
www.riss.kr
'후기' 카테고리의 다른 글
| 2022 ICPC 서울 리저널 인터넷예선 (0) | 2022.10.24 |
|---|---|
| 풀스택 웹사이트 개발기 (feat. FastAPI, Vue.js, TensorFlow, Docker) (0) | 2022.09.03 |
| 2022 모비스 대회 후기 (0) | 2022.07.05 |
| 원티드 쇼미더코드 후기 (0) | 2022.04.15 |
| 2022 구글 코드잼 Qualification Round 후기 (0) | 2022.04.03 |